[UPDATE: May 2020]: The site used in the below example has changed. I have modified the code to make it work. The codre concepts remain the same!
How easy is it to get JSON data with Scrapy?
The answer—very easy, even if you have basic knowledge of Scrapy.
On a side note, this simple task can be done using requests library. The purpose of this blog is to show how scrapy can be used with json directly. Scrapy is much more than just executing a GET request.
Background
The most common question that I get asked is which is the best tool for getting data from web pages
It is difficult to have a one size fits all answer to this as the use case is very different. I wrote on this earlier explaining these differences.
Using Scrapy
Scrapy is perceived to be difficult, just because it can do a lot of things.
It is actually very easy to get started if you follow the correct approach.
Getting Dynamic Data
Let’s see one example problem:
- Go to National Stock Exchange of India
- Get the data
- Save the data to Excel
Let’s try to solve this problem in the easiest way possible.
Understanding How the Web Page Works
Open this web page in Chrome, enable the developer tab. Go to Network and filter with xhr.
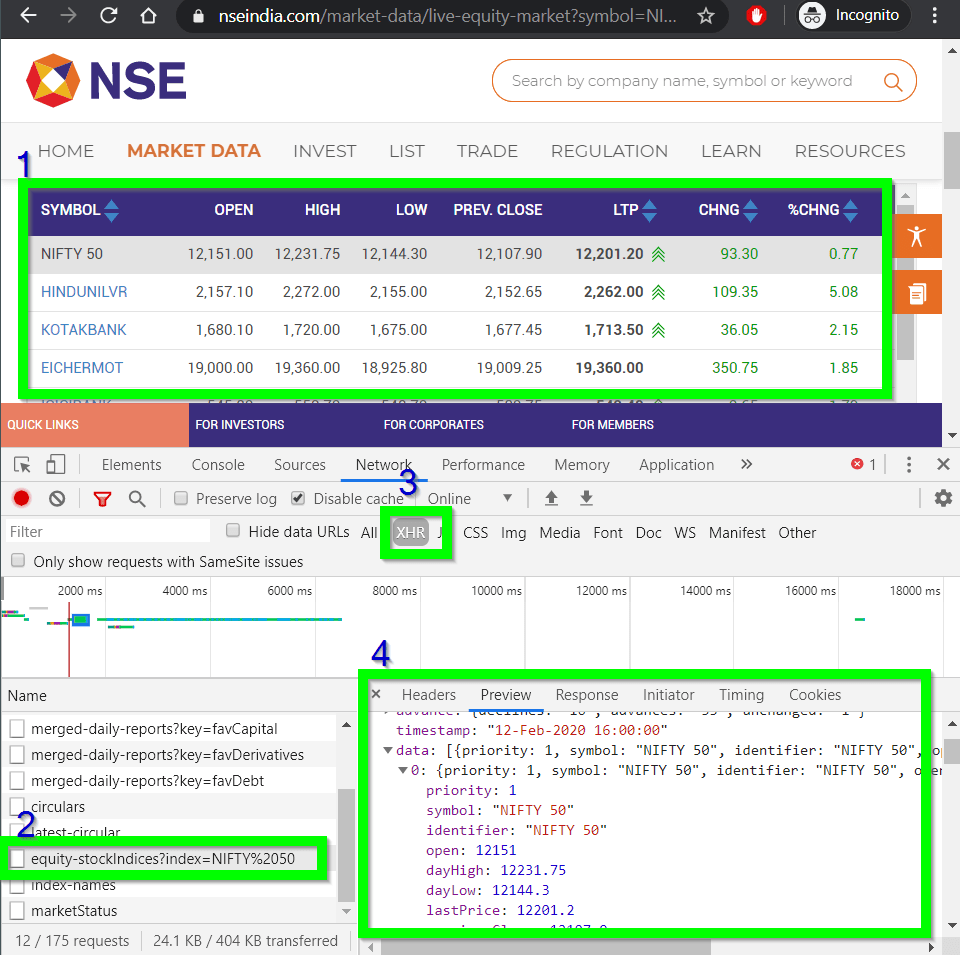
After examining this, we would know that the data is actually being loaded from a json file:
https://www.nseindia.com/api/equity-stockIndices?index=NIFTY%2050
This makes our work very easy. We don’t need to worry about selecting the elements or using more complex ways.
Ready to use Templates in Scrapy
Let’s create our scrapy spider.
First, Install Scrapy (Ideally in a virtual environment)
pip install scrapy
Now, create a simple spider with the default template. You can actually run the following command to see the list of available templets:
scrapy genspider -l
The output of this command is like this:
Available templates:
basic
crawl
csvfeed
xmlfeed
Now we can either use -l basic switch to specify the basic template, or skip the -l switch. The default template is basic, so this is not a problem.
scrapy genspider live nseindia.com
This will create live.py file with the skeleton of a Scrapy spider.
import scrapy
class LiveSpider(scrapy.Spider):
name = 'live'
allowed_domains = ['nseindia.com']
start_urls = ['https://nseindia.com/']
def parse(self, response):
passWe know that the request will return a JSON response. We can use Python’s json module parse it and return an anonymous object.
Scraping the JSON Data
Here is the the complete code. Notice custom_settings attribute — this is needed to send user agent with the requests.
import scrapy
import json
NIFTY_FIFTY = "https://www.nseindia.com/api/equity-stockIndices?index=NIFTY%2050"
class LiveSpider(scrapy.Spider):
name = "new"
start_urls = [NIFTY_FIFTY]
# Custom Settings are needed to send the User Agent.
custom_settings = {
'USER_AGENT' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
def parse(self, response):
json_response = json.loads(response.text)
listings = json_response["data"]
for listing in listings:
yield {
"Symbol": listing["symbol"],
"dayHigh": listing["dayHigh"],
}
Running the Spider
We can finally run scrapy with -o switch to move the output to CSV.
scrapy runspider live.py -o stocks.csv
Easy. Isn’t it?



