In this tutorial, we will learn how to download files with Scrapy. It may look daunting at first but is actually easy with its Crawl spider. This tutorial will walk you through all the steps.
The site that I have chosen for this tutorial is www.nirsoft.net. This site has a lot of small utilities and tools that have been lifesavers many times. has been my favorite for many years. I used Wireless Network Watcher to identify who is connected to my wifi and eventually take measures to secure it for example.
I thought it would be a good idea to have all utilities downloaded from this site. The perfect solution to this use case is web scraping where I can talk about crawlers and downloading files.
See the end of the article for complete source code.
Prerequisite
This tutorial shows how to download files with scrapy. Therefore, it assumes that you are familiar with the concept of web scraping and the basics of Python. If you don’t know what web scraping is, you will get a general idea from this tutorial.
I assume that you have at least working knowledge of Python though. This tutorial also assumes that you have at the very least, have played around with Scrapy.
Install Scrapy and Create Scrapy Project
If you want to download files with scrapy, the first step is to install Scrapy. Scrapy is the single most powerful framework for all kinds of web scraping needs. All other tools like BeautifulSoup4, Selenium, and Splash integrate nicely with Scrapy.
If you want to know the differences among these tools, have a look at this post. We won’t be using other tools in this tutorial though
As a rule of thumb, install it in a virtual environment. If you are not familiar with virtual environments, they are like virtual machines. Instead of a different operating system, they have their own packages installed. I am just going to install it at the user level.
pip install scrapy
Create a directory where you want to run this project and create a new Scrapy project
md nirsoft cd nirsoft scrapy startproject zipfiles
The output would be something like this.
New Scrapy project 'zipfiles', using template directory 'XXX', created in:
D:\nirsoft\zipfiles
You can start your first spider with:
cd zipfiles
scrapy genspider example example.comSpider Templates in Scrapy
There are four templates available in Scrapy. These can be used in different scenarios. You can use any of them to download files with scrapy. The final use depends on how you want to reach the pages with download links
It’s time to check the templates offered by Scrapy.
scrapy genspider -l
This outputs:
Available templates: basic crawl csvfeed xmlfeed
- Basic – General purpose spider
- Crawl – Spider for crawling, or following links
- csvfeed – Suitable for parsing CSV files
- xmlfeed – Suitable for parsing XML files
crawl : Most Suitable to Download All Files with Scrapy
For this scenario, the most suitable template is crawl.
Let’s create the basic structure of the spider (aka scaffold) using this template.
Always cd into the project directory before running. Your project directory is where you see scrapy.cfg file. Skip https:// part when providing the domain name. It will be added automatically.
cd zipfiles scrapy genspider -t crawl nirsoft www.nirsoft.net
This creates an “empty” crawl spider:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class NirsoftSpider(CrawlSpider):
name = 'nirsoft'
allowed_domains = ['www.nirsoft.net']
start_urls = ['https://www.nirsoft.net/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
Getting All the Links
Our crawler needs to know what links it should be following. This is where Rules and LinkExtactor come into the picture.
About Rules
The most important line of code here is the Rule.
Rules are what define links that should be followed. These are what save us for loops.
Rules can be created using many ways, including, but not limited to:
- allow
- deny
- restrict_xpaths
- restrict_css
The list is quite long. In this tutorial, we won’t need all those. If you want more information, take a look at the official documentation.
Analyzing the Links
One quick look at the nirsoft.net site will reveal that the details URL of utilities begin with the prefix utils. For example:
https://www.nirsoft.net/utils/web_browser_password.html https://www.nirsoft.net/utils/outlook_nk2_edit.html https://www.nirsoft.net/utils/usb_devices_view.html
It makes things easier as we can narrow down pages to crawl.
The update rule now looks like this:
rules = (
Rule(LinkExtractor(allow=r'utils/'), callback='parse_item', follow=True),
)So now our crawler is going to all the pages. Now it’s time to get the link to the download file.
Parsing the Crawled Page
Let’s navigate to any of the details pages, and Inspect the download link
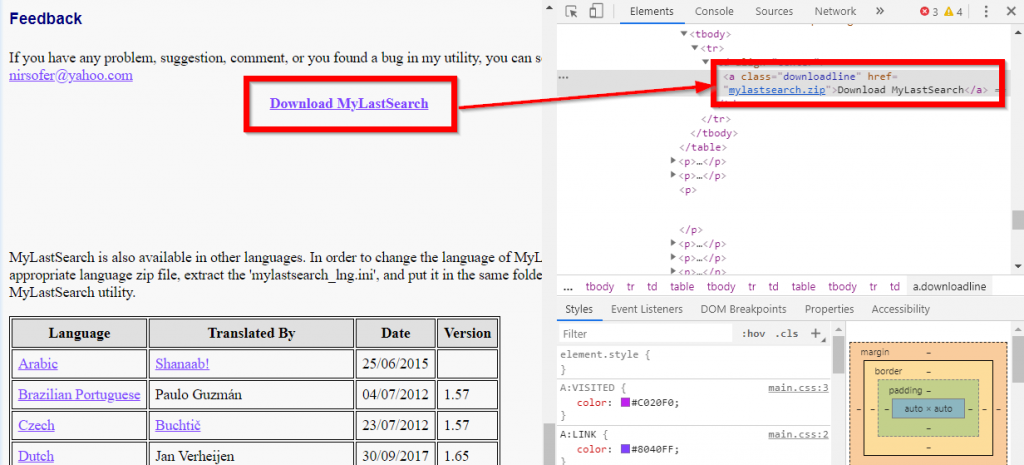
Sweet! the download link has the class downloadline. This looks pretty easy. Let’s use the CSS selector and extract the href attribute text:
def parse_item(self, response):
file_url = response.css('.downloadline::attr(href)').get()Relative Links to Absolute Links
The links are relative and we need absolute links. In the newer versions of Scrapy, its super easy. Just call response.urljoin() The code is now
def parse_item(self, response):
file_url = response.css('.downloadline::attr(href)').get()
file_url = response.urljoin(file_url)
yield { 'file_url': file_url }At this point, if we run the crawler, we will have a complete list of files.
scrapy crawl nirsoft
Next step, downloading the files.
Downloading Files
Let’s update the item class that was generated with the project and add two fields. NOTE: The field names have exactly the same for this to work. See Scrapy documentation.
class ZipfilesItem(scrapy.Item):
file_urls = scrapy.Field()
files = scrapy.FieldNow let’s create ZipfilesItem object in the spider. We would need to set the file_urls attribute value to the url of the files that we are downloading. Again note that it needs to be a list.
Here is the updated code.
def parse_item(self, response):
file_url = response.css('.downloadline::attr(href)').get()
file_url = response.urljoin(file_url)
item = ZipfilesItem()
item['file_urls'] = [file_url]
yield itemNow let’s enable the file download pipeline in the settings.py file:
ITEM_PIPELINES = {'scrapy.pipelines.files.FilesPipeline': 1}The last step is to specify the download location in settings.py. This should be a valid directory and the setting name is FILES_STORE. I am using raw strings to avoid escaping backslashes on windows:
FILES_STORE = r'D:\nirsoft\downloads'
That’s all we need. Now when we run the crawler, the files will start downloading.
scrapy crawl nirsoft
Limiting File Types Downloaded
We would see however that there are a few files which we don’t need. Let’s modify the parse_item method so that only zip and exe files are downloaded.
Further, let’s add one more field to ZipfilesItem class and set it before yielding. (See next section for why we are doing this)
This is how the parse_item looks at this point
def parse_item(self, response):
file_url = response.css('.downloadline::attr(href)').get()
file_url = response.urljoin(file_url)
file_extension = file_url.split('.')[-1]
if file_extension not in ('zip', 'exe', 'msi'):
return
item = ZipfilesItem()
item['file_urls'] = [file_url]
item['original_file_name'] = file_url.split('/')[-1]
yield itemKeeping Original File Names
The default implementation of the FilesPipeline does not keep the original file names.
How the File Names are Generated
For example, the URL
https://www.nirsoft.net/toolsdownload/webbrowserpassview.zip
will have its SHA1 Hash as
0f2ad6a88c00028c5029e9cec0fea3be5d7fe434
This file be saved as
0f2ad6a88c00028c5029e9cec0fea3be5d7fe434.zip
To resolve this, we need to write our custom Pipeline.
Custom Pipeline
We already have ZipfilesPipeline generated in our code, but we are not using it. We can either modify this or create a new Class.
If you look at ZipfilesPipeline class, it inherits from Object. We need to change it so that it inherits FilesPipeline. This would also mean importing the FilesPipeline in the file.
from scrapy.pipelines.files import FilesPipeline
class ZipfilesPipeline(FilesPipeline):
passControlling File Names
The next step is to override file_path method, which generates the file names.
The default implementation of file_path looks like this:
def file_path(self, request, response=None, info=None):
# DEFAULT IMPLENTATION
media_guid = hashlib.sha1(to_bytes(request.url)).hexdigest()
media_ext = os.path.splitext(request.url)[1]
return 'full/%s%s' % (media_guid, media_ext)As the last part of the request is the file name, we can update this function and remove all the hash generation parts.
def file_path(self, request, response=None, info=None):
file_name: str = request.url.split("/")[-1]
return file_nameUpdate Settings
Now let’s update the Settings file to use our custom Pipeline instead of FilesPipeLine
ITEM_PIPELINES = {'zipfiles.pipelines.ZipfilesPipeline': 1}Sometimes, you may see some errors because of user-agent and referer missing in the request. Let’s add these to the settings file.
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8',
'Accept-Language': 'en',
'Referer': 'https://www.nirsoft.net',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}Everything is ready now. Let’s run the crawler and within seconds we will have 252 files downloaded.
scrapy crawl nirsoft
How did you find this? Did you face any problems? Let me know!
Complete Source Code:
https://github.com/eupendra/Download_Files_Crawl_Spider




The tutorial doesn’t work. I get “NameError: name ‘ZipfilesItem’ is not defined” despite it clearly being defined. You don’t say what file it’s supposed to go into – where should I put it?
Looks like the item class was not imported.
I have verified and the code works. Check the complete code here – https://github.com/eupendra/Download_Files_Crawl_Spider
Thanks for the Github link, that was very helpful. And this was a cool spider!
One suggestion would be to list what parts of the code go into exactly which file in the tutorial. For example, it didn’t specify where to put the class ZipfilesPipeline code so I put it in the nirsoft.py. I’m sure it’s more obvious to experienced programmers but for a dummy like me I couldn’t figure it out.
Either way, thanks for a great tutorial, I learned a lot.